
1. JVM(Java Virtual Machine)
: JAVA를 배우게 되면, 제일 먼저 듣는 이야기가 바로 WORA(WORA : Write Once Run Anywhere) 사상이다. WORA는 JAVA Code가 JVM 기반에서 실행되기 때문에, 멀티 플랫폼(Windows, Mac. Linux, Unix, OS X 등) 환경에서 하나의 Code로 작성된 프로그램의 동작을 보장한다는 것을 의미한다.
일반적으로 프로그램은 OS와 Hardware에 종속된다. 하지만 JAVA는 JVM을 활용하기 때문에 프로그램이 OS로부터 독립적이게 된다.
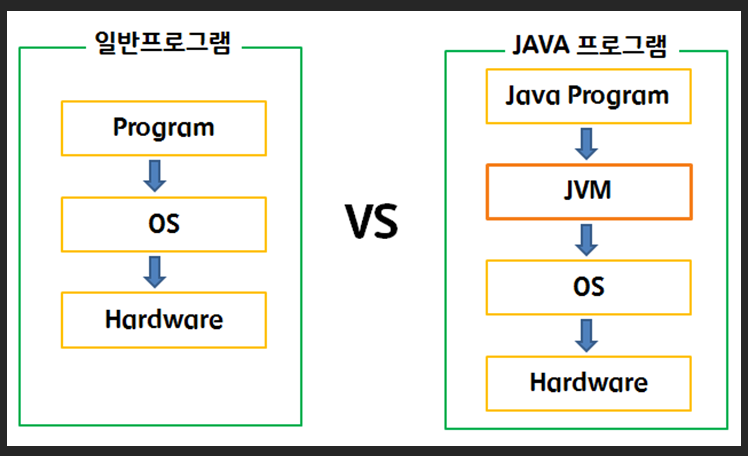
다만, JAVA로 만든 프로그램은 OS와 별개로 JVM을 실행한 뒤, 그 위에서 실행되기 때문에, 일반적인 프로그램보다 느릴 수 있다.(항상 그런 것은 아님.)
JAVA Code는 C언어와 달리 기계어로 Compile 되지 않고, JVM이 이해할 수 있는 Java Byte Code(.class)로 Complie되며, JVM는 이러한 Byte Code를 한 줄 씩 읽어 번역한 뒤, 실행하게 된다.(Interpret)
Compile VS Interpreter
- Compile 언어 : Coding - Compile - run
- Interpreter 언어 : Coding - run
- JAVA는 Byte Code로 Complie되고, 기동시에 한줄씩 Interpret하여 실행한다. 그렇다면 Java는 Complie 언어일까? Intepreter 언어일까?
- Complie 언어는 말그대로 작성한 코드가 실행되기 위해서는 Complie 과정을 거쳐서 실행하는 Machine이 이해할 수 있는 언어로 변경하는 것을 의미한다. Interpreter 언어는 별도의 Complie 과정없이 작성한 코드를 그대로 한줄씩 읽으면서 실행하게 된다. JAVA는 Complie 과정을 거치고, 실행시에는 Intepret하여 실행하기 때문에, 둘의 특성을 모두 가지고 있다고 할 수 있지만 엄연히 Compile 과정이 있기 때문에, Complie 언어에 속한다고 생각한다.
Byte Code를 JVM은 어떻게 실행하게 되는 걸까.
JVM의 동작원리를 살펴보기 위해서는 JVM의 특성과 JVM의 구조를 알아야한다.
2. JVM Structure
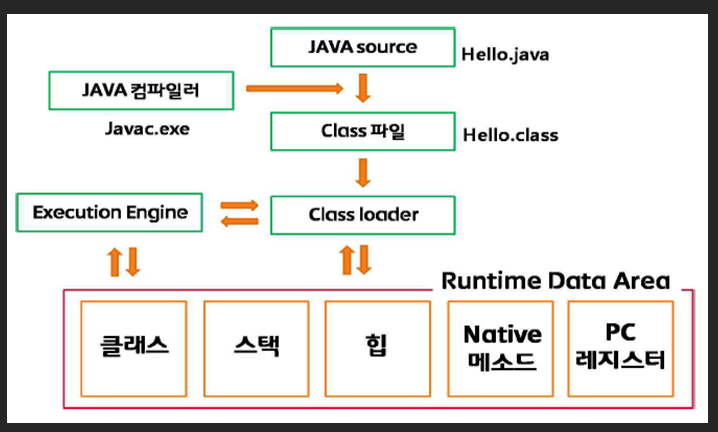
JAVA Compiler(Javac.exe)에 의해 Complie된 ByteCode(.class)들은 JVM의 ClassLoader System에 의해 Load 되고, Execution Engine에서 이 Class들을 한 줄 씩으로 읽어서 해석(Interpret)한다.
Execution Engine에서 해석된 ByteCode들은 JVM의 메모리(Runtime Data Area)에 할당되게 되는데, 그 역할에 따라 저장되는 영역과 방법이 달라지게 된다.
Class Loader
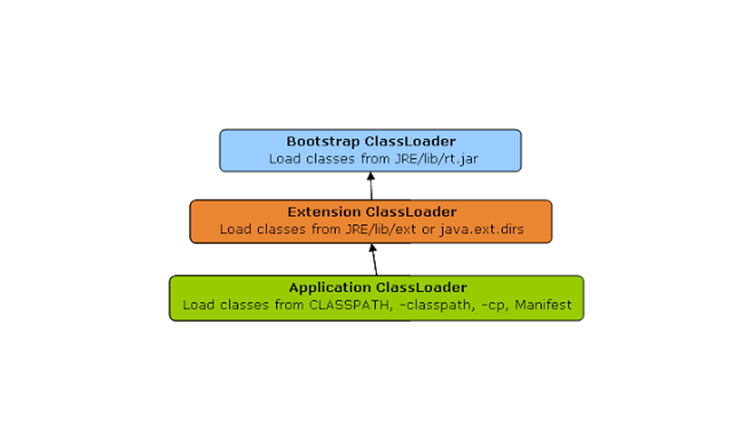
- JVM 시작시 Bootstrap Class Loder와 그 자식 Class Loader들을 생성하고, Object를 비롯한 Java Class들을 Loading한다.
- Load된 Class가 JAVA 명세에 맞는 지 Verify한다.
- Class가 필요로 하는 메모리를 할당하고, Class의 변수, 함수, 인터페이스를 구조화하여 Runtime Data Area에 Store한다.
Class Loader Structure
Execution Engine
- ByteCode를 Line 단위로 읽고 해석(ByteCode를 기계어로 변환)하여 실행한다.
- 한 줄씩 읽어서 실행하는 단점으로 인해 JIT(Just-in-Time) Complier를 사용하기도 한다. 다만 모든 Java Class에 JIT를 사용하지는 않는다(비용이 많이 듬)
Runtime Data Area(JVM Memory)
- JVM은 OS로부터 메모리를 할당받아, Runtime Data Area를 생성하고 사용한다.
- Class Loader에 의해 Loading된 Class들은 그 구분에 따라 서로 다른 JVM Memory에 보관된다.
- JVM Memory는 크게 5개의 영역(Method Area, Heap, Stack Area, Native Method Stacks, PC Register)으로 구분한다.
3. JVM Memory Structure
JVM Memory는 크게 5개의 영역(Method Area, Heap, Stack Area, Native Method Stacks, PC Register)으로 구분할 수 있다.
이중 Method Area, Heap, Runtime Constant Pool(Method Area에 속함)은 모든 Thread가 공유하여 사용하며, Stack Area, Native Mathod Stack, PC Register는
Thread 별로 하나씩 생성하여 사용한다.

Method Area(Static Area)
- JVM이 시작될 때, 생성된다.
- Class, Interface, Static 변수, Filed, 생성자, 메쏘드가 저장되는 영역이다.
- 각 Class와 Interface에 대한 런타임 상수들은 Runtime Contant Pool로 별도로 저장된다.
- Permanent Area 혹은 Permanent Generation으로 불리기도 한다.
- Perm Area에 대한 GC(Garbage Collection)는 선택사항이며, Perm Area에 GC는 드물게 일어난다.
- JVM이 실행되면서 Class Loader에 의해서 Loading된 Class 정보들은 Method Area에 저장되게 되고, 해당 Class의 Instance는 Heap Area에 저장되는 것을 구별해야한다.
Runtime Constant Pool
- Type(Class, Interface)의 모든 상수 정보가 저장된다.
- Type, Constant, Method, Field에 대한 Reference 정보를 저장한다.
- JVM은 Method를 실행 하기 위해 Runtime Constant Pool에 저장된 Reference를 참조한다.
Heap
- Type(Class, Interface)의 Instance와 배열(Reference Type)이 Runtime시 동적으로 저장되는 공간이다.
- 미리 설정해둔 메모리(시스템의 초기 메모리, 기동메모리로 불림)만큼을 한계로 그 안에서 사용되기 때문에, GC의 대상이 되는 영역이다.
Stack Area
- Thread가 시작할 때 할당되며, 메쏘드를 호출할 때마다 저장하고, 해당 메쏘드가 종료되면 제거한다.
- Static으로 선언되지 않은 메쏘드들이 Class 로딩시 준비된다.
- 메쏘드 내부에서 사용하는 Parameters, Local Variables, Operation 결과 값들도 저장된다.
- Primitive Type 변수들이 저장된다.(Reference Type은 Heap)
PC(Program Counter) Register
- Thread가 시작될 때, 생성되며, JVM 내부에서 처리한다.
Native Mathod Stack
- 자바 이외의 언어로 작성된 Native Code들이 실행될 시 저장되는 Stack Area
- JNI를 이용하여 C/C++로 된 Code 호출 시, Method의 Parameters, Local Variables, Operation 결과 값들이 저장(Byte Code)된다.
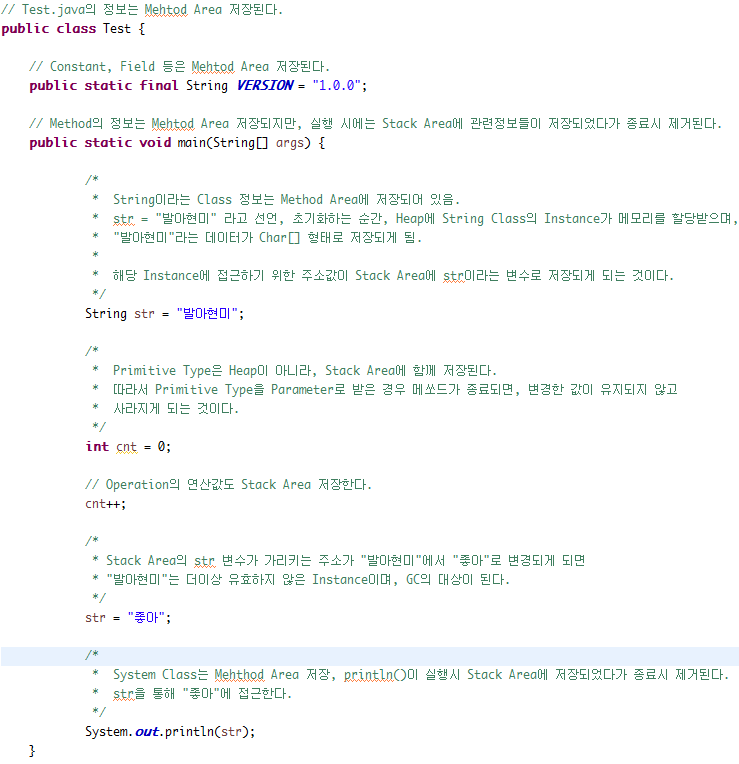
Sample Code
4. Heap & GC
Heap Area는 Young Generation, Old Generation, Permanent Generation으로 구분한다.
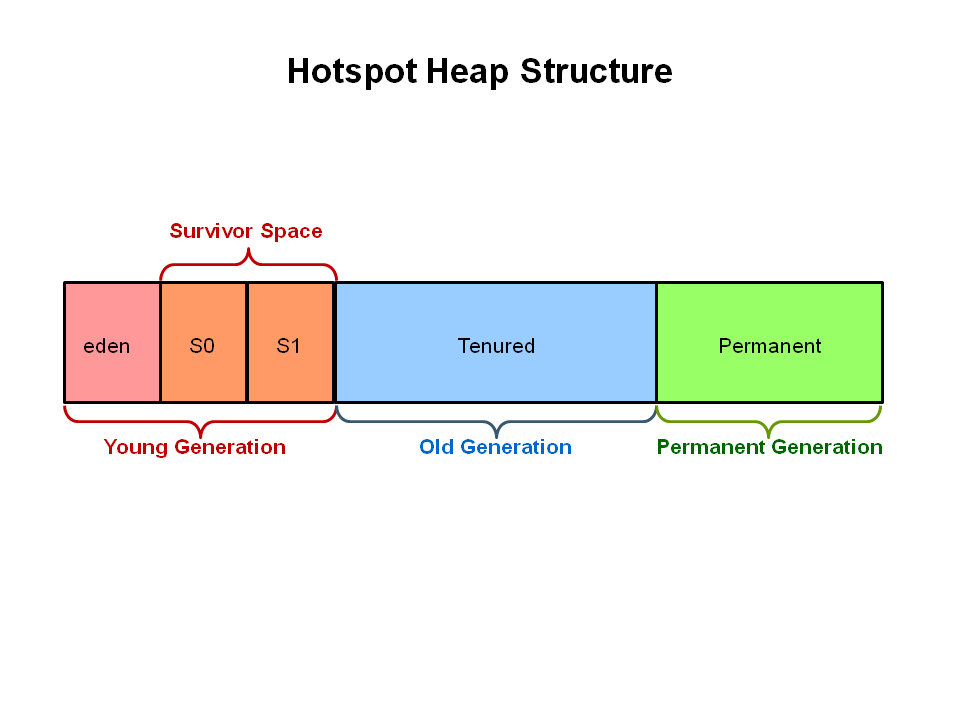
Permanent Generation
- JVM Structure의 Method Area(Static Area)에 해당한다.
Young Generation
- 객체가 생성되자마자 저장되는 영역이다,
- Young Generation의 객체가 참조가 해제(접근 불가능 상태, unreachable)되면, GC(Minor)가 일어난다.
- Young Generation의 객체가 일정시간 이상 유효하면 Old Generation 으로 이동한다.
Old Generation
- 참조가 유지되는 객체들 중 오래된 객체가 저장되는 영역이다.
- Old Generation에서는 일반적으로 데이터가 가득차면 GC(Major)가 일어난다.
- Young Generation보다 Old Generation의 할당된 크기가 크기 때문에, GC의 시간이 길다.
Heap Area에 저장된 모든 객체들은 언젠가는 운명을 맞이하는 데, 이를 Garbage Collection이 일어난다고 표현한다.
C의 경우 변수에 할당된 메모리를 소스코드상에서 임의로 해제가 가능하지만, JAVA에서는 Garbage Collector가 스스로 할당된 메모리를 해제하기 때문에, 개발자가 신경 쓸 필요가 없다는 장점이 있다.
다만, GC가 일어나는 동안은 GC를 수행하는 Thread를 제외하고는 모든 Thread들이 대기하므로, 너무 잦은 GC의 발생은 시스템의 성능에 영향을 줄 수 있다.
Young Generation의 경우, 2개의 영역(실제로는 3개)으로 구분할 수 있다.
Eden
- 새롭게 생성된 객체의 대부분이 저장된다.
Survivor
- Minor GC 이후 남은 Eden의 객체가 저장된다. 하나의 Survior가 가득 차게 되면 GC가 일어나게 되며, 살아남은 나머지 객체들은 다른 Survior 객체로 이동한다. 하나의 Survior 영역이 가득 차기 전까지 다른 Survior 영역은 비워진 상태로 존재한다. Survivor 영역 간을 오가는 객체가 시간이 지나면 Old Generation으로 이동한다.
Minor GC에 따른 Young Generation의 변화
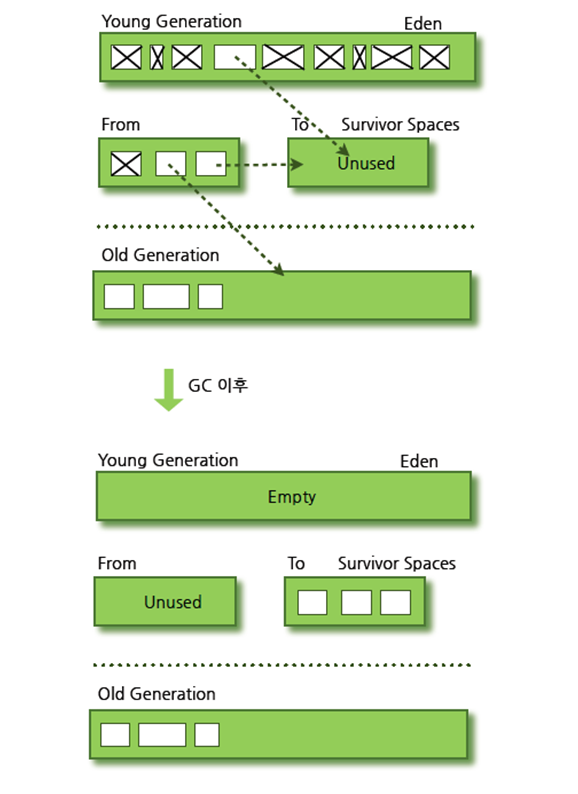
Old Generation에서 일어나는 GC를 Major GC 혹은 Full GC라고 하는데, GC를 수행하는 다양한 패턴을 설정할 수 있다.
Serial GC(-XX:+UseSerialGC)
- Heap Area의 객체들 중 유효한 객체를 식별하고, 순차적으로 삭제한다. 살아남은 객체들은 Heap Area의 앞에서부터 채운다.
Parallel GC(Throughput GC, -XX:+UseParallelGC)
- Serial GC와 동작방식이 동일하나, GC를 수행하는 Thread가 여러개다.
Parallel Old GC(-XX:+UseParallelOldGC)
- Parallel GC의 동작이 개선된 방식이다. JDK 1.7.4 이상부터는 Parallel GC와 Parallel Old GC가 동일하게 동작하게 된다.
CMS GC(Low Latency GC, -XX:+UseConcMarkSweepGC)
- Heap Area의 객체들 중 유효한 객체들을 식별하는 단계를 나눠서(식별, 확인)한다. 유효한 객체들이 실제로 참조하는 객체들이 있는지 확인할 때는 다른 Thread들이 멈추지 않는다. 식별이 종료되면, 유효하지 않은 객체들을 삭제하는 데, 이 과정에서도 다른 Thread 들이 멈추지 않는다. 오직 최초에 유효한 객체를 식별하는 과정에서만 Thread들의 동작이 멈추기 때문에, GC로 인한 지연이 최소화된다. 다만 소모하는 자원이 많다.
G1 GC
- Young, Old의 구분없이 전체 Heap Area를 바둑판 형태로 분할하여 사용하다, 해당 영역이 꽉차면 바둑판의 다른 영역에 유효한 객체를 할당하고, 해당 영역에 대해서 GC를 수행한다. JAVA 7부터 정식으로 포함되었다. 성능적인 면에서 우수하다.
Ref :
왜 JVM의 구조를 이해해야 하는가
NAVER JVM Internal
JD-Clipse Home
JAVA의 Class Loader
Oracle JVM 명세
변하는 것은 변하지 않는다 - JAVA JVM
훈마로의 보물창고 - 자바 메모리 구조
자바에 메모리가 저장되는 구조와 원리
자바 메모리 구조
NAVER GC
NAVER GC 튜닝